プログラマーであればまず選択したくないフォーマット、CSV。
CSV が嫌で XML になって、XML もだるいから json に。読み書きライブラリも揃ってるし、もう全て json でいいじゃん! と思ってる人も多いでしょう。
近年プログラマーになった人は、CSV 扱ったことない人もいるかも。
ただ一つ、XML / json には欠点があるのです。それは…。
一般人が拒否反応を起こす。特に手書きが無理。
「手書きが辛いなら、なんかツールかませば(作れば)いい」という発想は当然一般人には出来ません。
CSV ならノートに書くような見た目だからなんとか…こういうレベルの人がデータを作る事ために、CSV はまだまだ存在し続けるでしょう。
金融とか、不動産系とか多い。資産持ってる人って大抵 PC のリテラシーがひk…
そんなわけでチャチャっと CSV を読み込むプログラムを書いてみました。
思ったより面倒で、頭の痛い作業でした。
CSV を理解する
GOLD POINT CARD+,VISA,gold,visa,,No,0000XXXX00000000
楽天銀行,rakuten,bank,https://www.rakuten-bank.co.jp/,支店,999
こんな感じの「カンマ区切りのデータ」「改行=1行分のデータ」がCSVです。
これだけのルールであれば、データを取得するプログラムもこの通り。簡単です。
SQL とか Linq 的書き方が好きな人には、これでもウザいと思われるのかもしれない。
var text = "GOLD POINT CARD+,VISA,gold,visa,,No,0000XXXX00000000\r\n楽天銀行,Kaz,rakuten,bank,https://www.rakuten-bank.co.jp/,支店,999";
// 行に分割
string[] lines = text.Replace("\r", "").Split('\n');
var rows = new List<List<string>>();
for (int i = 0; i < lines.Length; i++)
{
var cols = lines[i].Split(',');
rows.Add(new List<string>(cols));
}
// rows[0][0] = "GOLD POINT CARD+"
// rows[1][0] = "楽天銀行"
// rows[1][1] = "kaz"
エラー対策一切してませんがたったこれだけ。簡単ですね!
おそらくほとんどのサイトでは、こんな感じの読み込みコードが紹介されていると思います。
た だ し、このプログラムで読み込める CSV には制限がつきます。
- 文字列の中にカンマを含めたくなったら?
- 文字列の中に改行を入れたくなったら?
例えば、こんなデータ。

これをエクセルで CSV 保存すると、こんなテキストに。
GOLD POINT CARD+,VISA,gold,visa,,"No: 0000XXXX00000000
user: username
pass: password"
楽天銀行,rakuten,"bank,
mainbank",https://www.rakuten-bank.co.jp/,"支店: 999
普通: 0000xxxx00-00"
この CSV は当然、先に紹介した解析コードは全く通用しません。赤い部分を誤解析し、おかしなデータを吐き出します。
人が見てもわかりづらい。パッと見で、支店:999 が何行目のデータかわかるでしょうか。
この CSV は以下の拡張したルールが含まれています。
文字列の中にカンマを含めるルール
AAA,BBB,CCC,dd, ddd,EEE
「dd, ddd」が1つ分のデータだったとしても、このままでは2つ分のデータと判断される…。
この問題を解決するために、CSV はこのように(いかにも場当たり的ですが)ダブルクオーテーションで囲います。
AAA,BBB,CCC,"dd, ddd",EEE
改行を含めるルール
ダブルクオーテーションで囲っていれば「dd, ddd」の中に改行を入れることもできます。
AAA,BBB,CCC,"dd,
ddd",EEE
ダブルクオーテーションの中にダブルクオーテーション…!
AAA,"BB""B",CCC,"dd,
d""dd",EEE
ダブルクオーテーションの中でダブルクオーテーションを記述したい人のために、"" って2つ重ねてね! というさらに場当たり的なフォーマットになりました。
これで " があったら次の " までが文字列…といった取り方は封じられました。
改行まで含めるとワケがわからなくなってきましたね。
このように CSV は、「何も知らない一般人には直感的だが、読み取り側はちっとも直感的じゃない」フォーマットなのです。嫌われる理由が理解できたでしょうか?
列の間にスペース入れてるやつがいる
見やすくしよう。そんな気遣いでデータをこんな風にしている人もいます。
カンマの後ろにスペース入ってるのがわかるでしょうか。
困ったことに、入ってたり入ってなかったりします。改行が1つでもあれば不毛な見やすさですし、気遣いは嬉しいのですが困惑するのは我々、プログラマーです。
AAA, BBB, CCC,"dd,
d""dd", EEE
頑張って読み取ってみる
こういう風に取りたい。
AAA, "BB""B", CCC ,"dd,
d""dd",EEE
↓
data[0] = "AAA"
data[1] = "BB\"B"
data[2] = "CCC"
data[3] = "dd,\r\nd\"dd"
data[4] = "EEE"
元のデータは罠だらけです。とくに data[3] がひどい。1つ分のデータがどこまでなのか解析するのが大変面倒。
色々考えましたが、今回は1カラムごとにデータ取っていくプログラムにしました。Regex などで前処理する方法もよさそうですが、今回は考えずに。
一応上にあげた問題は全て対処しています。
// test string
var text = "AAA,BBB,CCC,\"dd,\r\n ddd\",EEE";
var rows = new List<List<string>>();
var columns = new List<string>();
for (int pText = 0; ; )
{
int pComma = text.IndexOf(",", pText) - pText;
int pQuote = text.IndexOf("\"", pText) - pText;
int pCrlf = text.IndexOf("\r", pText) - pText;
if (pCrlf >= 0 && (pComma < 0 || (pCrlf < pComma)) && (pQuote < 0 || (pCrlf < pQuote)))
{
// CRLF
var c = text.Substring(pText, pCrlf).Trim();
pText += pCrlf;
columns.Add(c);
}
else
if (pQuote >= 0 && (pComma < 0 || (pQuote < pComma)))
{
// " ~ "
int end = pText + pQuote+1;
// "" がないか確認(あれば飛ばす)
for (int e = end; ; )
{
int end0 = csvdata.IndexOf("\"", e+1);
int end1 = csvdata.IndexOf("\"", end0+1);
if (end1 == end0+1)
{
e = end1;
continue;
}
else
{
end = end0;
break;
}
}
end -= pText;
var c = csvdata.Substring(pText + pQuote+1, end-1).Trim();
pText += end+1;
c = Regex.Replace(c, "\"\"", "\"");
columns.Add(c);
}
else
if (pComma >= 0)
{
// ,
var c = text.Substring(pText, pComma).Trim();
pText += pComma;
columns.Add(c);
}
else
{
// end of data
var c = text.Substring(pText, text.Length - pText);
if (string.IsNullOrEmpty(c) == false)
{
columns.Add(c);
}
break;
}
if (text.Length > pText)
{
if (text[pText] == '\r')
{
if (columns.Count > 0)
{
rows.Add(columns);
columns = new List<string>();
}
pText += 2; // \r\n
}
else
if (text[pText] == ',')
{
pText += 1; // ,
}
}
}
if (columns.Count > 0)
{
rows.Add(columns);
}
// debug log
foreach (var cols in rows)
{
Debug.Log(string.Join(" >> ", cols));
}

全然簡単じゃなくなってしまった。とくに ”” のくだりは見返したくない。
パフォーマンスには多少配慮しているので、膨大なデータとか突っ込まない限り問題はないと思いますが、テストはしていません。バグは…あるかも。(あったらすみません)

さらに実用を考えると…
データないのに、なんかある
エクセルで CSV を保存すると、こんなテキストになってしまう事があります。
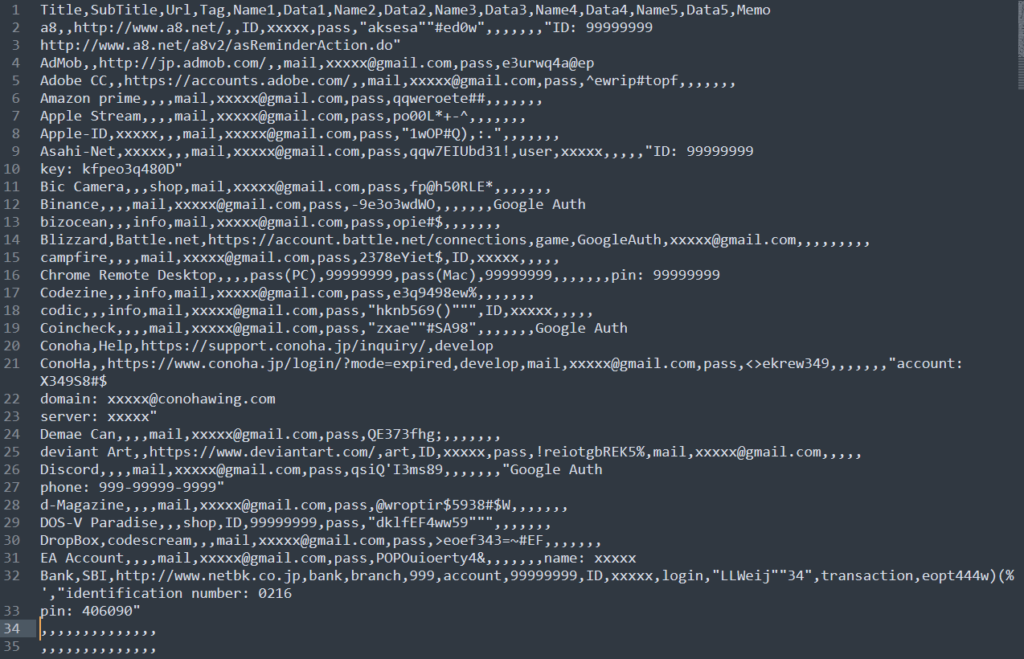
34行目以降のカンマ連発は何?? ってなるんですが、エクセルのではただの空欄になっており、見た目では一切わかりません。
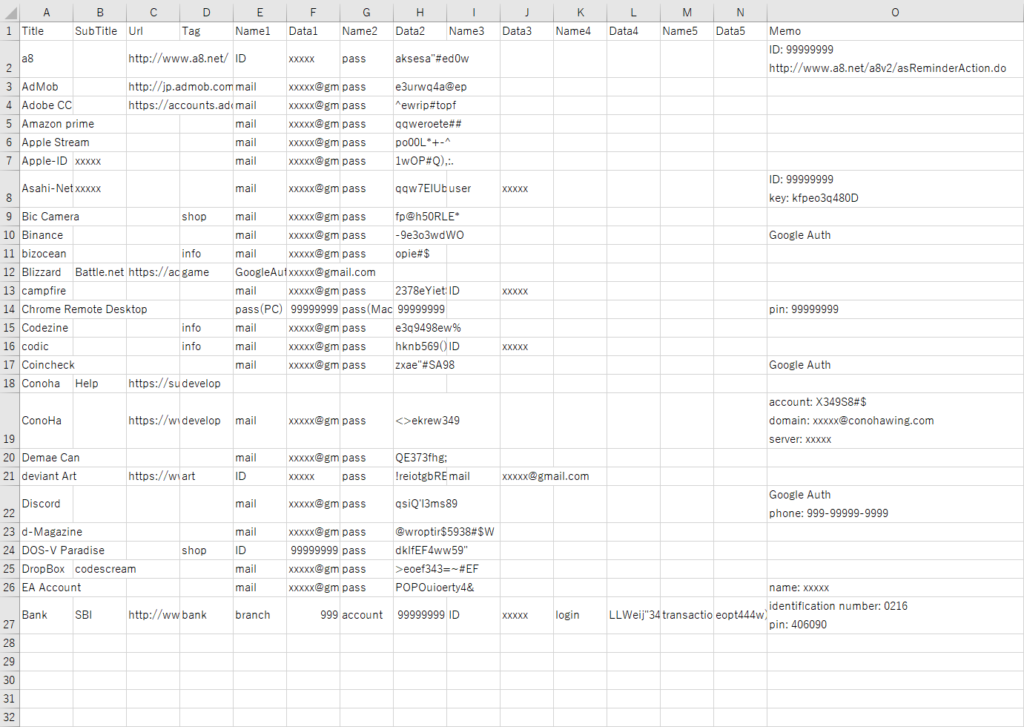
このように「何もないのに、データがあることにされる」というのも CSV のお困りポイントです。
(エクセルで何もない行を選択して削除すれば消せなくはない…けど、そんな運用したくない)
そんなわけで、行になにもない場合、その行はスルーする…といった気遣いは我々プログラマー諸兄の手に委ねられます。
列の数が必ず等しいと思うな
こちらはエクセルで保存した場合は問題ありませんが、テキストエディタでうっかり1行だけ列を消してしまう、なんて事が起こりえます。
テーブルなんだから、列の数全部等しいでしょ! とか思ってるとこのうっかりによって最悪プログラムが例外を出して止まる…なんてことも。
そうならないように優しく交通整理するのも当然、我々の仕事です。
行・列の順番変えるとか
さすがにそんなわけないでしょ??? と言いたいところですが、「一般人が大好き」「手で修正しやすい」ということは起こり得るヒューマンエラー…。
行の順番はともかく、列の順番変えられるのはかなり厳しい。
それを防ぐため、1行目にヘッダ名を持ってきておくと(面倒だけど)一応列の入れ替えに対応できますが、今度はヘッダ名が違うなんてヒューマンエラーも考えられる…。
どんだけエラーチェックすればええねん。
考えれば考えるほど、CSV は地獄です。
可能であれば、CSV は使いたくない
この記事を書いたお陰で、改めて CSV さんの恐ろしさを再認識することができました。
このコードが皆さんのお役に立つことも(多分)ないでしょう…。