byte[] はデータのバイナリ化、通信、暗号化等々よく使われる型ですが、プログラムで実際に必要になるのは別の型である事が多いです。
使う度にググってる自分に気づいてしまったので、記事にしておくことにしました。
C# の記法なので、unity に限らず使えます。
unity 以外の方は、Debug.Log を Console.WriteLine に変更してください。
string text = "0123456789"; byte[] data = System.Text.Encoding.UTF8.GetBytes(text); Debug.Log(BitConverter.ToString(data)); string result = System.Text.Encoding.UTF8.GetString(data); Debug.Log(result);
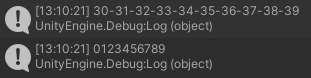
これだけで OK です。わかりやすいですね!
Encoding についてちょっと解説
だいぶ UTF8 全盛になってきたので、エンコードを意識しないプログラム民も増えてきたのかもしれません。
ですが、古いシステムはいまだにエンコードの悩みを抱えている事も多いので、知識として知っておくといいのではないかと思います。
お前の見ている世界が全てだと思うな…
なんか厨二っぽく言ってみましたが、普段私たちが見ている文字は「コンピューターが byte[] をいい感じに解釈して、文字として表示してくれている」ものです。
コンピューターが解釈しているのは、こっちの方。

これをいい感じに解釈して "0123456789" に表示してくれています。
厳密なルールを知りたければ、ASCII 配列とかでググるといいよ!
このルールは1つだけではありません。無数…とはいいませんが結構流派があります。
試しにさっきのコードを次のように変更してください。
string text = "0123456789"; byte[] data = System.Text.Encoding.UTF32.GetBytes(text); Debug.Log(BitConverter.ToString(data)); string result = System.Text.Encoding.UTF8.GetString(data); Debug.Log(result);

UTF8 を UTF32 にしただけでなんでやねん、ってくらい長くなりました。これが UTF32 のエンコードです。
また、このエンコードを UTF8 で戻すことはできません。日本語は日本語同士、UTF32 は UTF32 同士でしかわかりあえないのです。
このせいでエンコード問題が起こります。
かつてデータベースは EUC-JP、サーバーは UTF32 で返し、クライアントは Shift-JIS だと思って文字を描画…こんな世界線がありました。正しく文字が描画できるはずもありません。これが文字化けです。
この決着をつけるため、歴史上色々ありました(なんか前に記事書いた気がする…)が、いまでは UTF-8 に統一するようになってきたと感じています。
とはいえ、今でも Windows 標準のツールは Shift-JIS が大好き、UTF-8 しか対応していないテキストエディタなどで文字化けを見ることができます。


メモ帳でかつてはデフォルトだった Microsoft の ANSI は Shift-JIS の拡張らしい。現在は UTF-8。
Windows は大抵最後まで過去の資産を残そうとする。これは技術者としては腹が立つことも多いけど、それゆえに非技術者の人が末永く使える OS になっているのでしょう。
後実は、ゲーム業界のプログラマも Shift-JIS が大好きだった。
理由は多分、自分たちが作り上げた C / C++ の日本語パーサーが Shift-JIS 向けだから。
中国語や韓国語に対応するために、泣く泣く Shift-JIS を諦めていたりすると思う。




